Intuition
Compared to RNN, CNN tackles a different kind of issue. When working with images or data that has spatial structure, it turns out that the conventional way of converting the input data to a 1D array (a flattened version) produces some lackluster results. Intuitively this makes sense, since certain properties of the 2D data are lost when flattening it into a 1D array.
CNN is a different kind of neural network layer that allows for more dimensions - \(h\) for height, \(w\) for width, and \(d\) for depth. From a training perspective, the \(h\) and \(w\) are the kernel size (dimensions) and \(d\) represents the number of filters (features).
How it works
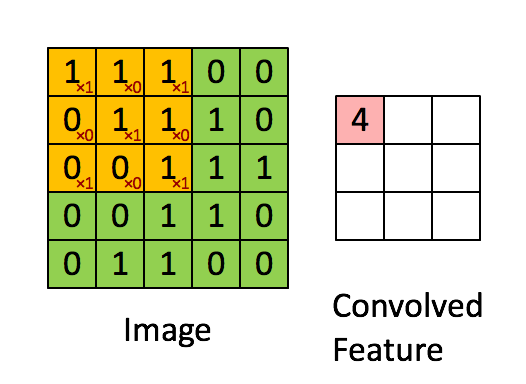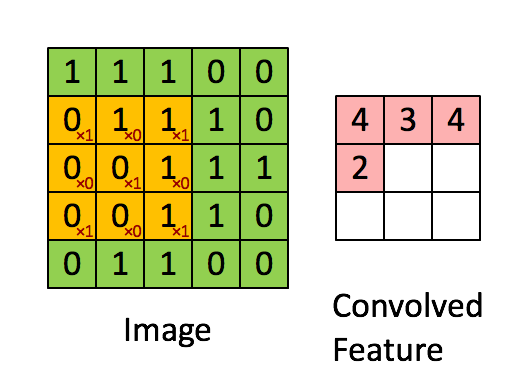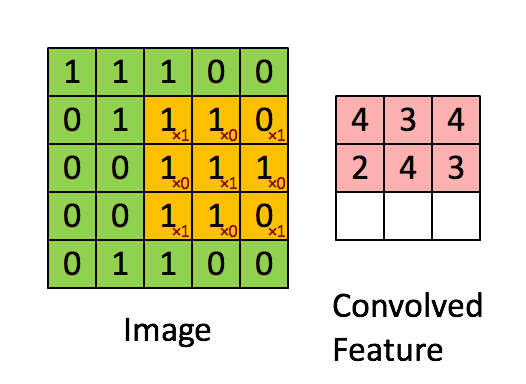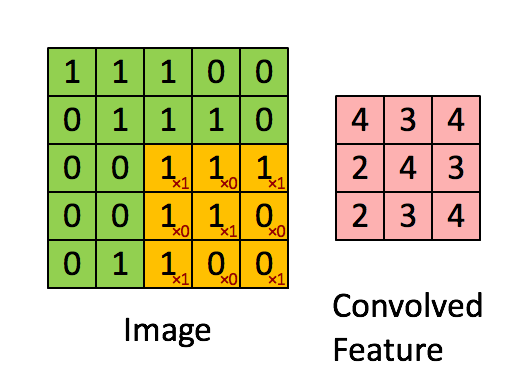
In a nutshell the CNN layer does convolution on the original matrix to output a shrunken down version of the matrix with aggregated weights.
In the gif above:
- The convolutional neural network layer has a kernel of size \(3x3\).
- A filter that is the same size as the kernel \(3x3\) is applied to the original image. Note how the filter itself has \(x1\) diagonally but \(x0\) everywhere else - essentially, this filter is trying to see if there are 'X' shaped sub-images inside the original Image matrix.
- We do element-wise multiplication and sum up the result. Then we record the result in the Convolved Feature output matrix which is also \(3x3\).
- We shift the filter to the right by 1 (this is the stride operation) and repeat steps 2 to 4 until we can't slide the \(3x3\) block on the Image matrix any further. When this happens, we shift the filter down by 1 and start from the far left position again, until we can't slide any further downwards.
- At this point we should now have a filled convolution matrix.
Pooling
To reduce the spatial dimensionality of the CNN layer outputs and curve overfitting, a max pool layer can be added right after it.

This improves the overall computational time of training in the network by reducing the number of trainable parameters.
Issues
CNN layers are computationally expensive
- We can circumvent this by using separable convolutional layers (i.e. Keras Conv2D) to reduce the number of computations significantly. This is useful especially for training on smaller devices (mobile, Raspberry Pi, etc.) and generating predictions in a more latent manner.
Real World Applications
- Object Detection
- Race/Gender Classification
- Face Generation (with Generative Modeling)